
数据空间需要新型基础设施
国家数据局成立后于2023年首次提出了数据基础设施体系(如图1),左上的网络设施、安全设施是信息基础设施的核心,右下的算力设施、数据流通设施是新型基础设施的核心。
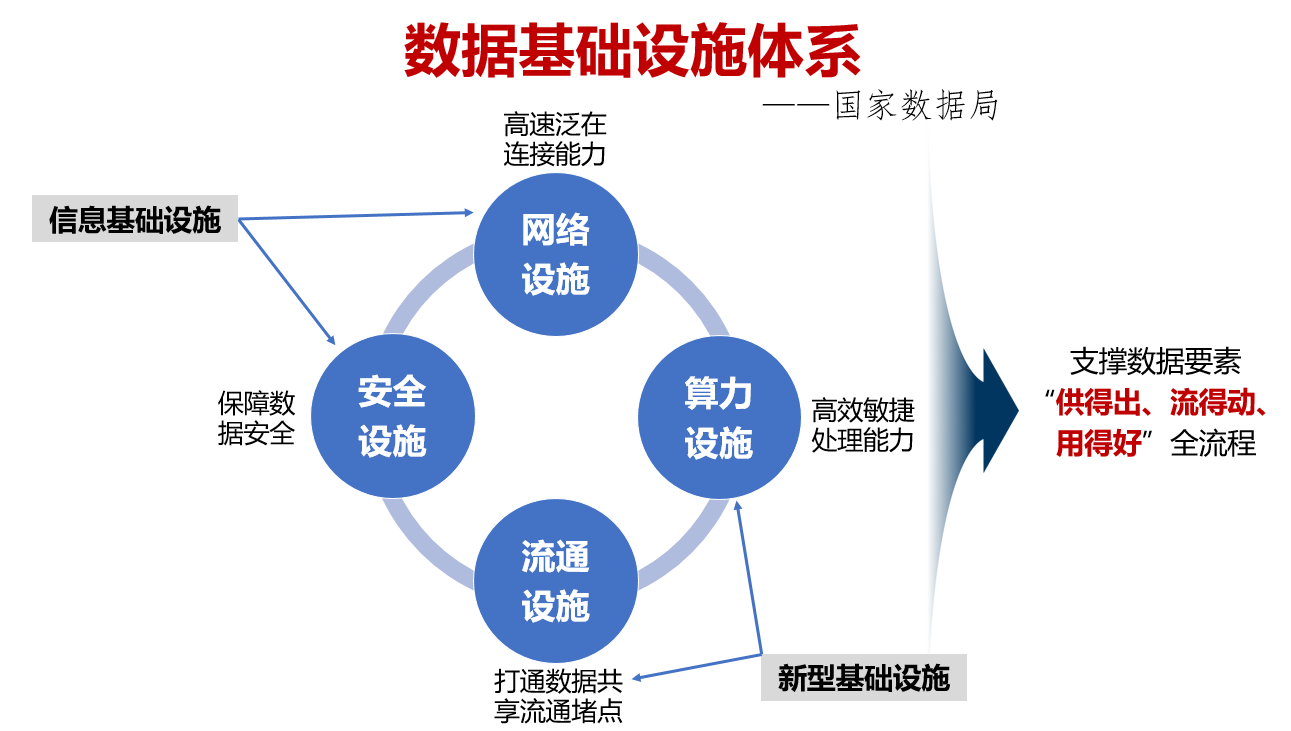
图1:国家数据局提出的“数据基础设施”体系图
本文的主要观点是:从信息时代演进到智能时代的本质变化就是网络空间(Cyberspace)架构在信息空间层上增加了数据空间层。数据基础设施就是要实现人工智能三要素——数据、算力、算法的基础设施化,以支撑智能时代核心资源的广域共享与人工智能低门槛的广泛应用。
一、 网络空间是如何形成的?
空间就是有结构的一种物质客观存在形式。从空间的角度看,网络空间(Cyberspace)是如何形成的?
首先,网络空间的基础是计算机系统,从大型的主机到小型的服务器,再到微型的微机,以及移动型的智能手机和现在嵌入型的智能物端(embodiment thing)等,都是单个的计算机系统。然后,建立连接,就有了计算机网络,形成了网络空间的物理层——计算机空间。由网络IP地址和网络传输协议构成的互联网结构,是计算机空间的基本结构,其主力应用是各类网络应用,如电子邮件(email)、远程终端(telnet)。
然后,通过万维网(World-Wide Web),形成了网络空间的逻辑层——信息空间。其基本抽象是网页(web page),核心功能都是通过网页的生成、组合、显示(html)来实现的,网页的地址和链接协议(http)构成了信息空间的基本结构,主力应用是各类网页应用,如搜索(Baidu)、网购(Alibaba)、即时通信(WeChat)。
这样形成了网络空间中的信息基础设施(information infrastructure),包括四层:底层是通信基础设施,包括光网络、接入网、卫通网、物联网;中间层是互联网基础设施,包括IP网、域名服务等;上层是万维网的各大信息枢纽网站;最后的第四层是云计算基础设施,包括超算中心、IDC、公有云、私有云等。
当前正在形成网络空间的虚拟层——数据空间。下面将探讨数据空间的本质,数据空间的新型数据基础设施,以及如何支持数据空间的主力应用AI+。
总结一下,网络空间是一个三层架构(如图2)。最下层是计算机空间,基本结构是互联网,连接所有计算设备,加工人类抽象出的知识。中间层是信息空间,基本结构是万维网,连接所有网页,加工信息。最上层是数据空间,基本结构是数据场(注:该概念由吴曼青院士首先提出),连接所有数据件,加工人机物三元世界产生并汇聚的数据,生成模型,再通过AI+溶入(embodiment)到信息世界、物理世界的各个过程中。

图2:网络空间的三层架构
二、 数据空间存在吗?
数据是客观存在的(being),并在网络空间中被数字化了,在信息空间里被处理后成为网页中的信息。但是,数据空间独立出来的价值是什么?网络世界里的数据集合是否具备独立的基本结构呢?
1. 处理对象
网络空间处理对象的演化规律是从知识到信息,再到数据(如图3、4、5)。网络计算空间是连接所有计算设备,加工人类符号化的数理知识,网格计算(Grid Computing)是这个空间的算力基础设施化;网络信息空间是连接所有网页,加工人类社会向数字空间投影的各类信息,云计算(Cloud Computing)是这个空间的算力基础设施化;网络数据空间是连接所有数据件与模型库,加工全量数据形成智能模型,算力网(Computility)是这个空间的算力基础设施化。由计算机学者在上世纪60年代提出的算力基础设施化的理想正在一步步变成现实。
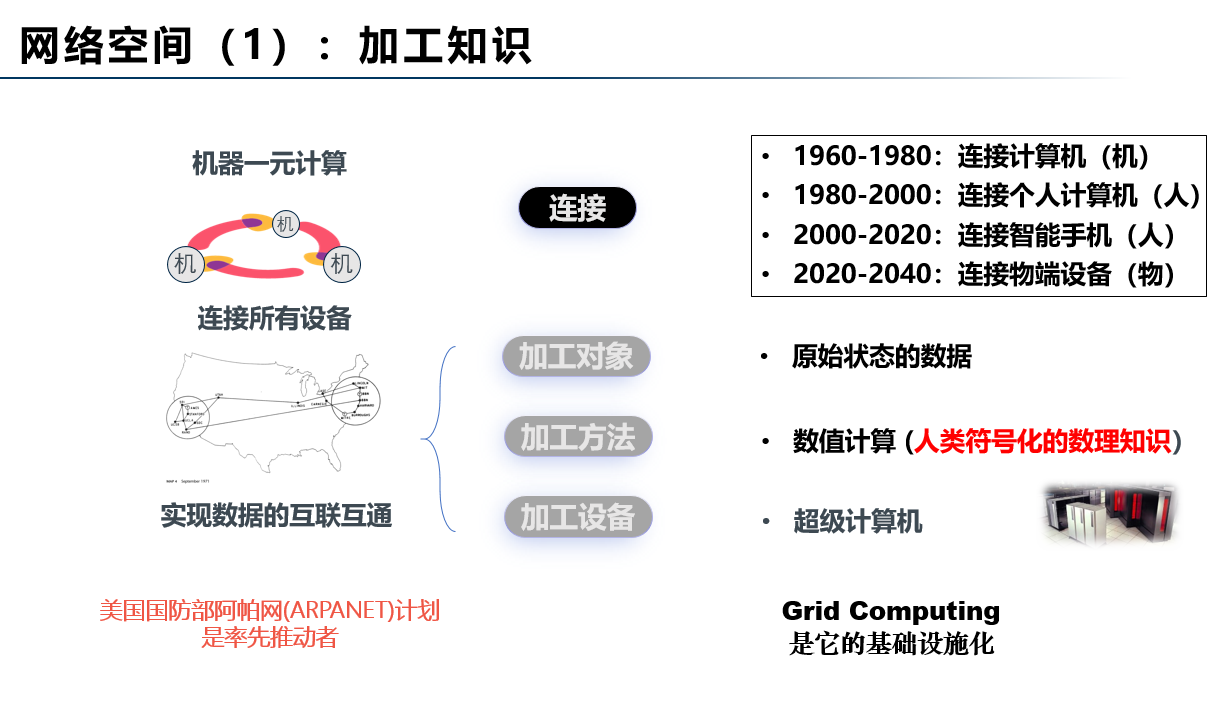
图3:网络计算空间
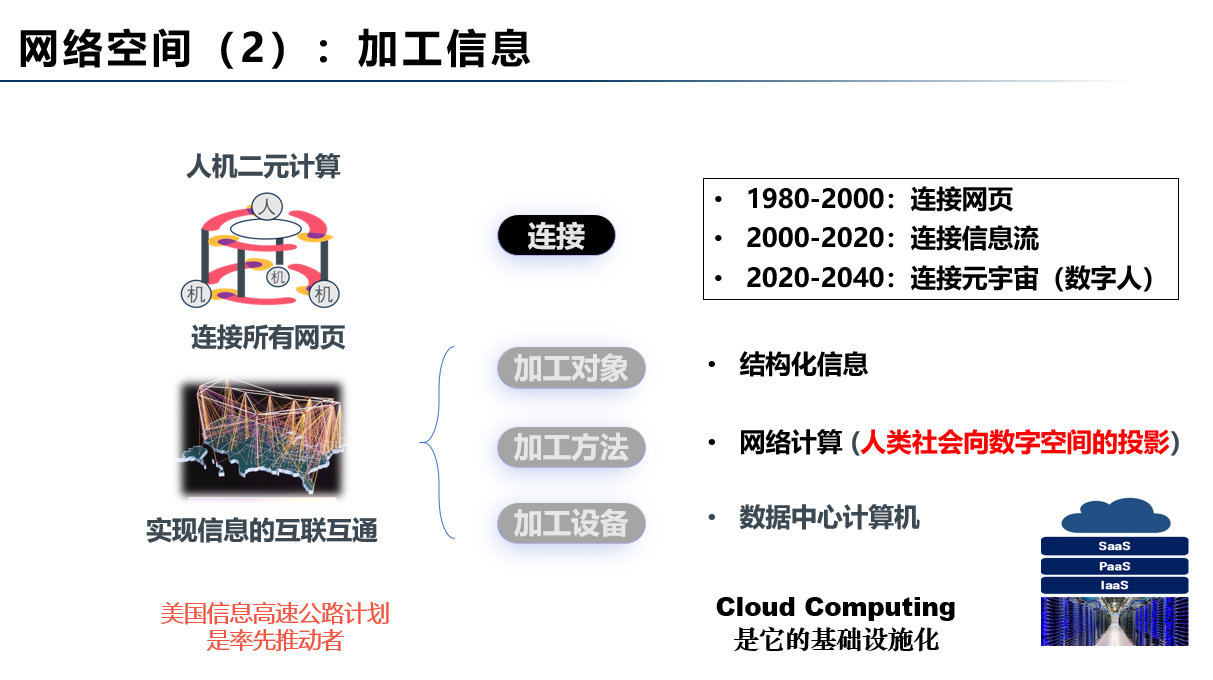
图4:网络信息空间
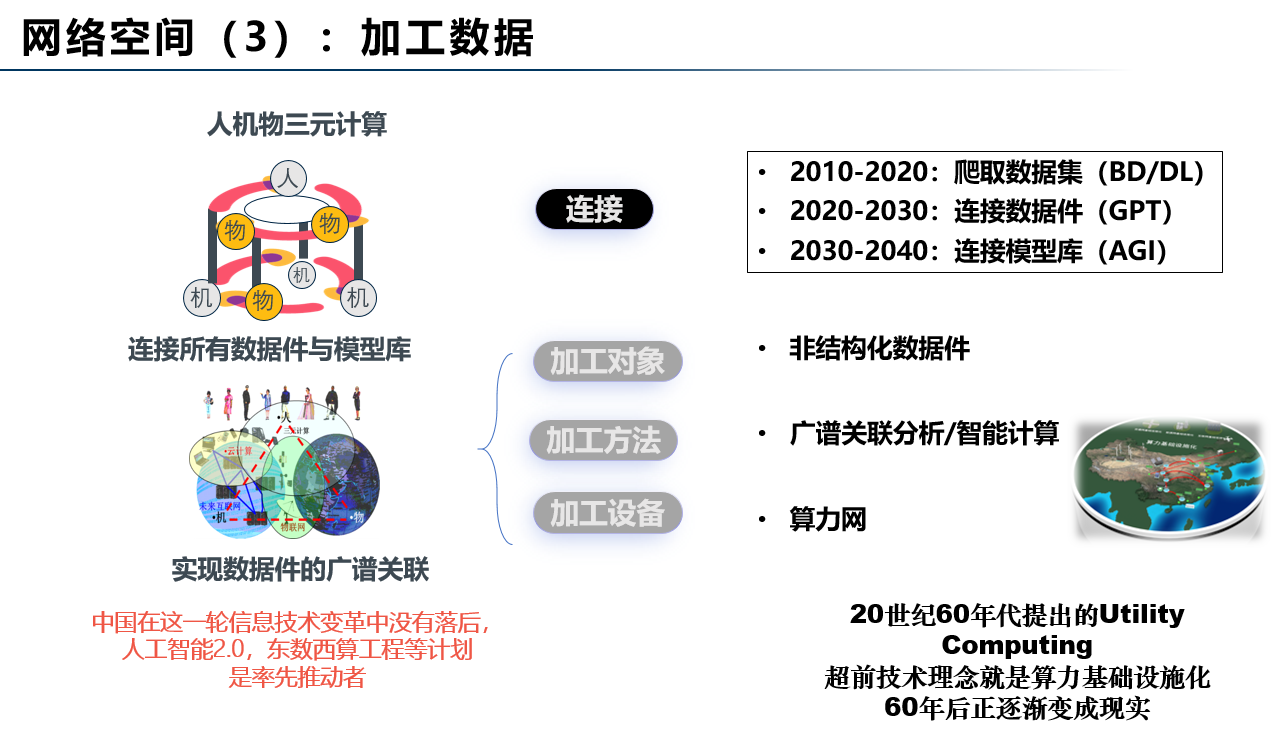
图5:网络数据空间
网络数据空间预计会分成三个发展阶段,其中:2010-2020年是基于爬取数据集的大数据(BigDada)与深度学习(DeepLeaning);2020-2030年是基于连接数据件的大模型深度学习;2030-2040年阶段,我们预期是大模型连接成网,未来通用人工智能不是一个大模型能覆盖的,会有很多大模型,可能通用人工智能(AGI)需要连接网络空间里所有的模型。 除了人工智能大模型,科学计算也有很多模型,也需要与人工智能大模型用某种方式连接起来。
2. 价值增值方式
所有信息变换的目的都是为了价值的不断增值。网络信息空间的高价值活动的特点是“核裂变”,追求无限扩大信息可达的边界,梅特卡夫定律(Metcalfe's law)指出:网络信息空间的价值与用户数的平方成正比。而网络数据空间的高价值活动的特点是“核聚变”,追求无限扩大数据件的边界,无限压缩知识数字化表达的语义空间。从这个角度看问题,LLM是用Transfomer算法点火成功的互联网数据空间的一个大型聚变反应的产物。我们也大胆预测一个定律:网络数据空间的价值与广谱关联数据件数量的平方成正比。从数据空间看,智能是数据的百炼成钢(如图6),还需要提炼出若干数据增值的范式。
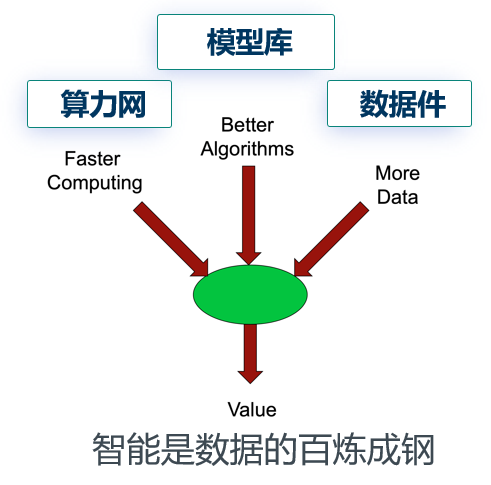
图6:网络数据空间的价值增值方式
3. 数据空间存在结构吗?
数据空间是否存在基本的结构体,目前学术界还没有形成共识。最早试图破解这个基础难题的学者是图灵奖获得者罗伯特・卡恩,他是TCP/IP互联网协议的发明人,在20世纪80年代创造了“国家信息基础设施”(NII)一词,后来被称为“信息高速公路”。他提出了数字对象架构(Digital Object Architecture,DOA)的概念,以便实现在互联网上对各种数据资源进行管理与互操作,并给出了以数字图书馆为代表性应用的一个参考实现。
国内北大等团队基于数字对象架构提出了数联网的构想。数联网的基本思路是基于软件定义,通过以数据为中心的开放式软件体系结构和标准化互操作协议,将各种异构数据平台和系统连接起来,在“物理/机器”互联网之上形成的“虚拟/数据”网络。数联网的技术思路是沿用Web的思路,实现数据集合的定位发现、交换调度、互操作访问。数据对象是否需要像Web信息那样在全世界互联网上可见可用呢?还是只需要支持区域内共享?需要深入思考。
吴曼青院士在国家数据局推出将数据要素化作为新质生产力的背景下,带领国家数据空间战略研究团队提出数据空间的基本结构是数据场的思路。核心思路是面向数据要素化中的数据流通与交易、价值深加工,提出一套围绕数据基本抽象的标准、协议、广谱关联方法与核心系统。
三、 数据件
智能时代赋予了数据新的两重属性,即资源要素属性与价值加工属性。数据的资源要素属性包括产生、获取、传输、汇聚、流通、交易、权属、资产、安全等要素;而数据的价值加工属性包括有效提升价值的主要要素,如加工对象(如数据件)、加工工艺(如广谱关联算法)、加工动力(如算力网)等。
数据要素化后将会出现多个产业形态。以矿产资源为例,有采矿业、大宗矿物交易市场、冶炼业等。在数据方面,将来也对应有采“数”业、数据交易市场、数据加工业等。数据要素化也需要多个技术体系的支撑,例如,需要传感器/物联网技术体系来解决数据“供得出”的难题,需要数据元件概念与数据金库系统(注:该概念由中国电子陆志鹏副总经理首先提出)来解决数据汇聚与“流得动”的难题,需要数据件技术体系来解决数据“用得好”的难题。除了技术体系,还要有经济政策层面的创新,包括:数据资产在资产表中怎么并表、数据使用怎么才安全合规、数据集定价的锚点如何选择等。
数据的基础设施化主要解决数据的大规模汇聚与流动的问题,包括国家数据枢纽的建设、数据流通与交易设施的建设。“数据20条”推出后,这方面在国家、地方、行业等多个层面都有了很多的实践,需要进一步归纳出最有效的模式。
支撑数据的价值加工属性方面则欠缺系统性的工作。数据加工技术从早期的数据管理(DB),到数据检索(IR),再到数据分析(BI/BD),直到现在的数据深加工(AI),一直在发展与演进。数据的不断“解耦”是演进的主要规律,它也带来数据基本抽象的变化(如图7)。第一次解耦是数据与应用程序的解耦,目标是屏蔽数据访问的复杂性,降低应用系统的开发门槛,数据基本抽象是ER模型,核心系统有数据库/数据仓库。第二次解耦是数据与业务系统的解耦,目标是屏蔽数据汇聚分析的复杂性,降低企业级系统的开发门槛,数据基本抽象是KV模型,核心系统有数据湖。第三次解耦是数据生产与消费主体的解耦,目标是屏蔽数据流转与使用的复杂性,降低数据要素社会化供给、流通与应用的门槛,数据基本抽象是数据件模型(Dataware),核心系统有数据场。
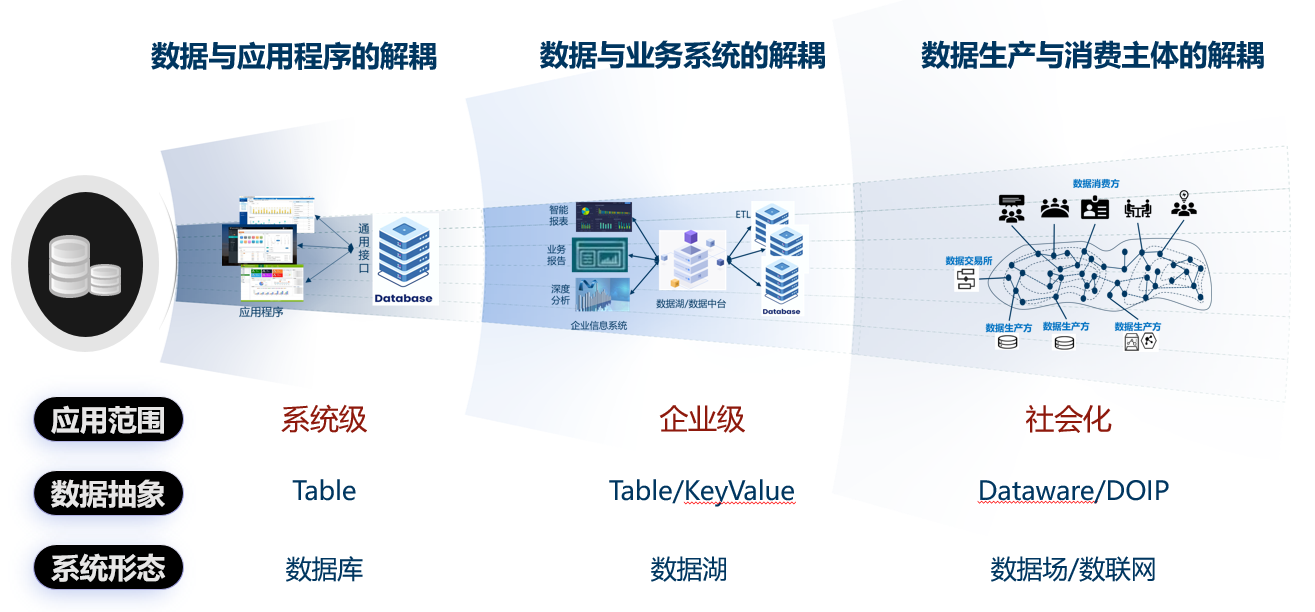
图7:数据的不断“解耦”带来基本抽象的演化
数据件(Dataware)是数据要素流动与使用的基本单位,通过对异质多源数据的语义、结构、基本操作等进行标准化封装,使得数据要素与数据主体、数据应用“解耦”,让数据在不同主体、不同应用系统间高效地流转与使用。在云计算中,容器(docker)是对应用程序及其依赖的封装,让算法在不同平台上实现一键运行,它是一个可以参考学习的对象(如图8)。
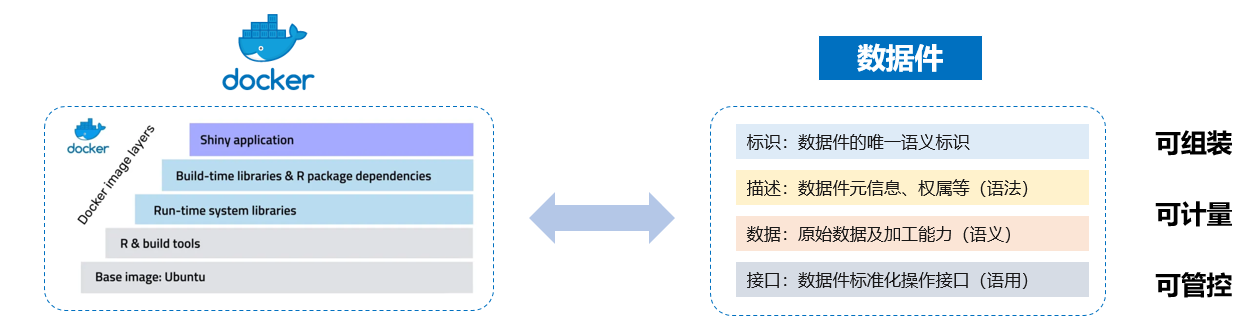
图8:容器(docker)和数据件(Dataware)
当前的数据加工流程是“原始数据AI/BD算法”,即原始数据直接送到AI/BD算法中进行处理。数据要素化后的数据加工流程应该经过“原始数据数据件数据场AI/BD计算”三级解耦,实现数据价值的梯次转化(如图9),数据的全社会加工效率才能更高。
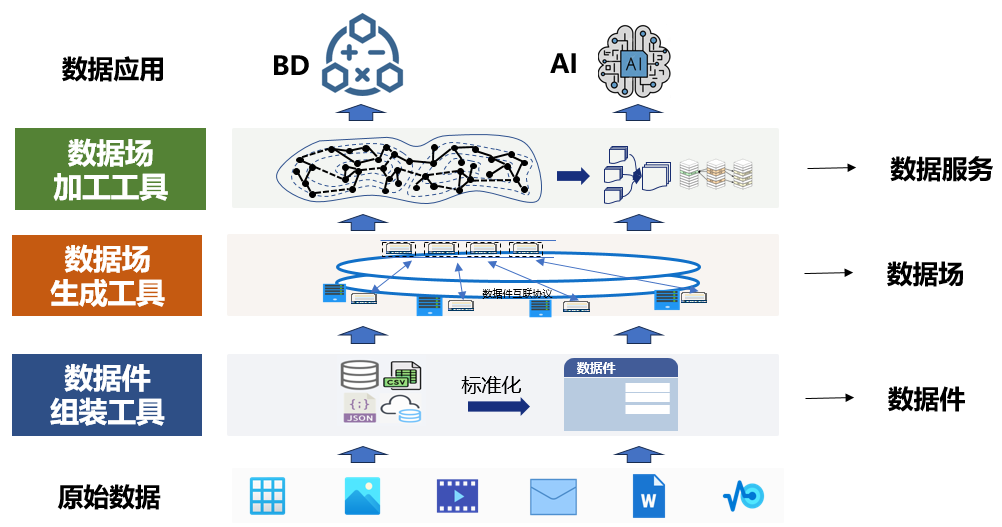
图9:数据件的生产链
第一步,原始数据先送给数据件组装工具。以AI大模型应用场景为例,通过数据件构造工具实现预训练、指令微调、向量数据的快速构造与组装,再由大模型训练软件调用,大幅简化传统数据工程的工作量(如图10)。
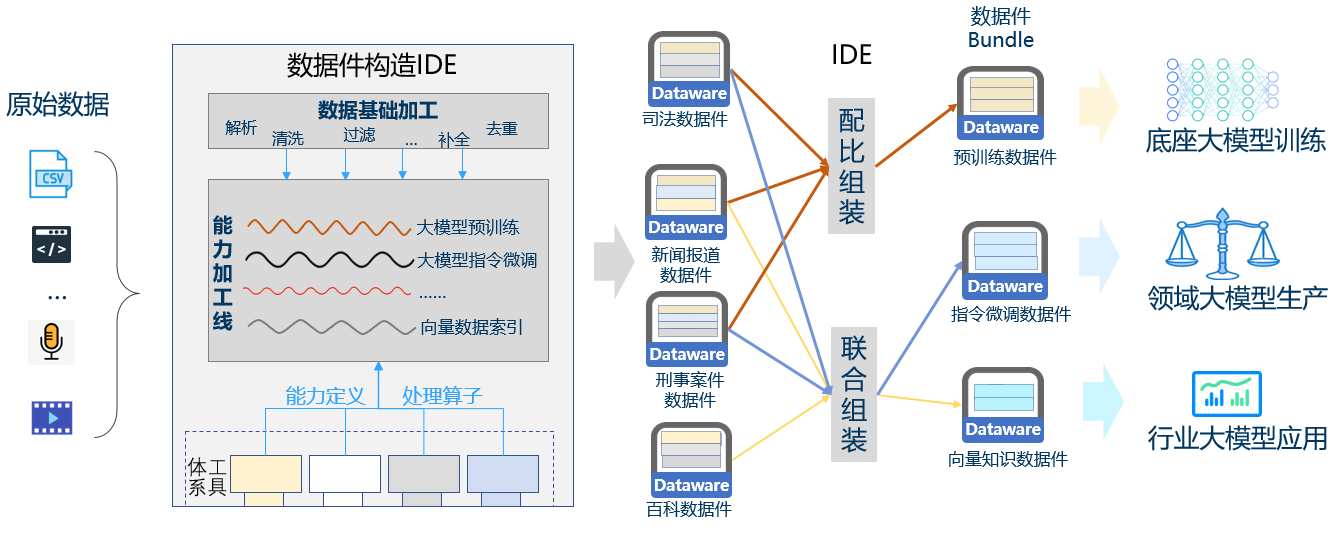
图10:数据件组装工具
第二步,数据件送给数据场生成工具,其中包括数据件互联协议和数据场生成描述语言。数据件互联协议实现数据件寻址、传输的透明化、标准化,让用户不再关注数据件的存储位置,实现广域意义上的存算解耦。数据场生成描述语言,通过对数据件需求的形式化定义与需求转换逻辑,实现多维度、多类型“数据场”的按需生成,实现对数据件快速、精准地在线获取。
第三步,数据件最后送给数据场加工工具,其中包括各类广谱关联算法。广谱关联算法覆盖对数据件的基本运算操作,实现对数据件的横向融合加工(如BD分析)与纵向深层提炼(如AI大模型)。同时,数据件生产链还要支持内生的安全保障(如图11)。
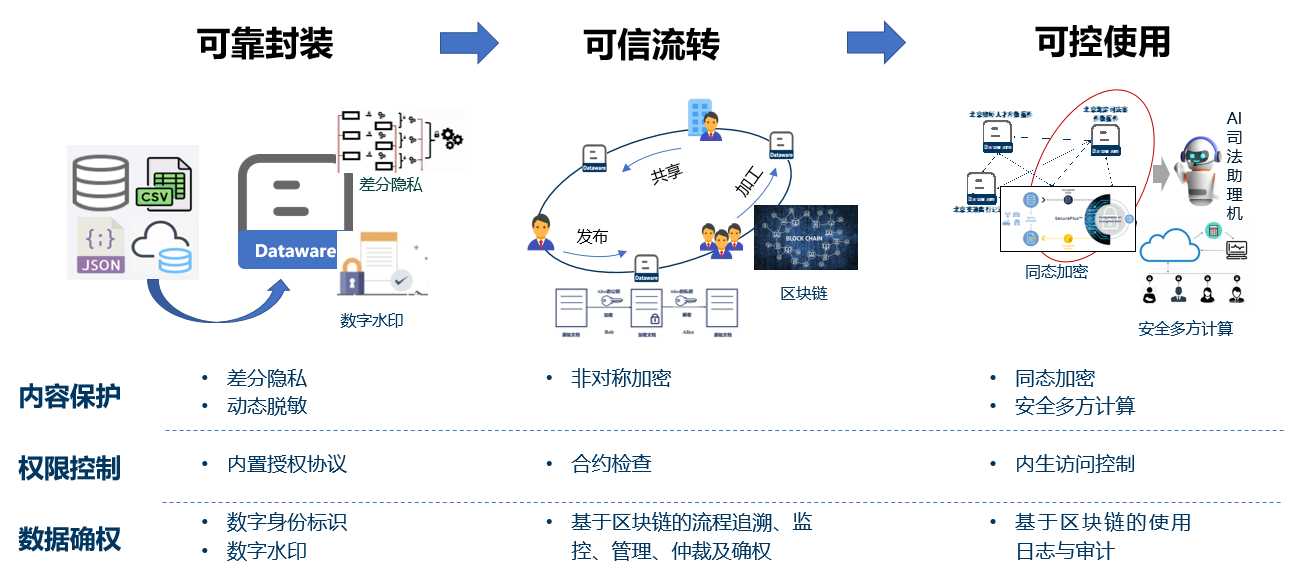
图11:数据件生产链内生安全保障
四、 算力网
性能一直是计算部件与系统能力的表征,为什么还要提出算力这个新概念?算力这个术语对应的英文单词是Computility(注:《中国计算机学会通讯》,2022年12月),其本义是从产生算力的角度对计算性能的通俗表达,衍生之后更注重消耗计算资源产生效用的能力,是从消耗算力的角度表达。定义一个国家的算力指数不仅要统计处理器芯片数量,还要体现对数据进行深加工与精炼能力。算力概念提出的本质是要推进算力的基础设施化,而算力网是算力基础设施化的第三阶段。算力网不是把计算设备联网(这一点互联网已经做到了),而是算力资源被基础设施化后以服务的形式提供出来,在全网消费。因此在算力网上流动的不是计算能力,而是消费算力的算力网页、任务闭包等新容器。
第一阶段的算力基础设施(算力1.0),是网格计算,共享私属的超算资源,使超算中心资源易使用。第二阶段的算力基础设施(算力2.0),是云计算,将互联网龙头企业的闲置算力资源虚拟化后对公众提供租用服务,对算力用户来说,做到了算力的弹性可扩展和变买为租,有力地支撑了互联网时代Web信息的广域共享。随着近年来智能物端(无人系统、智能机器人、智能硬件)的蓬勃发展、人工智能技术的大爆发,算力网的概念应运而生,它是第三阶段的算力基础设施(算力3.0)。算力网是继美国提出网格计算、云计算之后,首次由中国提出的概念。算力1.0和2.0是构建在信息空间之上,而算力3.0必须构建在数据空间之上。
算力网将异地、异属、异构的分布式算力站,在逻辑上构建成“一台大电脑”,提供更优适配、更低成本和更加易用的智能算力服务,有力支撑智能时代数据、算力、算法的广域共享。
国家发改委推动的“东数西算”工程是我国在算力网领域最早的政府行动计划,有力地推动了我国率先实现算力的基础设施化。“东数西算”工程稳步推进两年取得很大的进展,算力资源集中向八大国家算力枢纽内汇聚,特别是西部枢纽节点充分利用了绿电资源。在技术创新方面也取得了明显的成效,包括:异属算力并网、异构智算统一纳管、算力站间直连网络;算力跨域调度、算网协同调度、广域数据快递;超算互联网应用模式、城市与省域算力网运营等。“东数西算”工程正在形成自己的技术体系(如图12)。
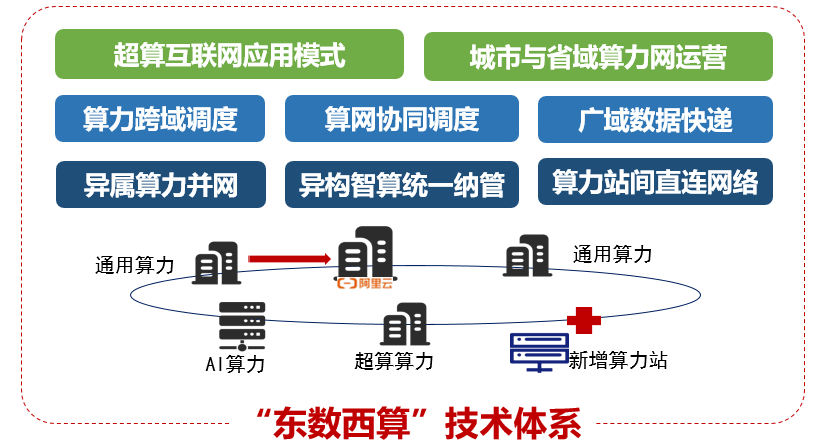
图12:“东数西算”技术体系图
算力网在三个方面存在巨大技术挑战。
第一个巨大挑战是可在算力网上流动的算力基本抽象,即算力要素流动与使用的基本单位,可称之为任务闭包(task closure)。算力基本抽象应包括任务编排的原子化抽象、运行时资源空间管理抽象、算力资源一体化封装抽象三个层次,按技术发展演进来看(如图13),从最初的线程/进程/CPU时间片,发展到微服务/容器/虚拟机,再发展到现在的任务闭包/网程/算力池。在IT 1.0的主机阶段,并行与分布式编程是在线程抽象的基础上构建,进程是对资源分配与调度的抽象,可以跨CPU时间片运行;在IT 2.0的互联网阶段,云计算实现了计算能力的虚拟化,容器是对基础软硬件资源的封装,微服务是对编程的原子化抽象,可以跨虚拟机运行;在IT 3.0的智能阶段,对全网计算资源要用“一台大电脑”的思路提供新的抽象,任务闭包可以在端边云异构平台上流动和运行;网程是对端上的物理机、边上的虚拟机、云上并网的算力池,进行统一封装,形成一个智能应用的资源空间;算力网上的异地、异属、异构的算力资源并网后要形成一体化的算力池。
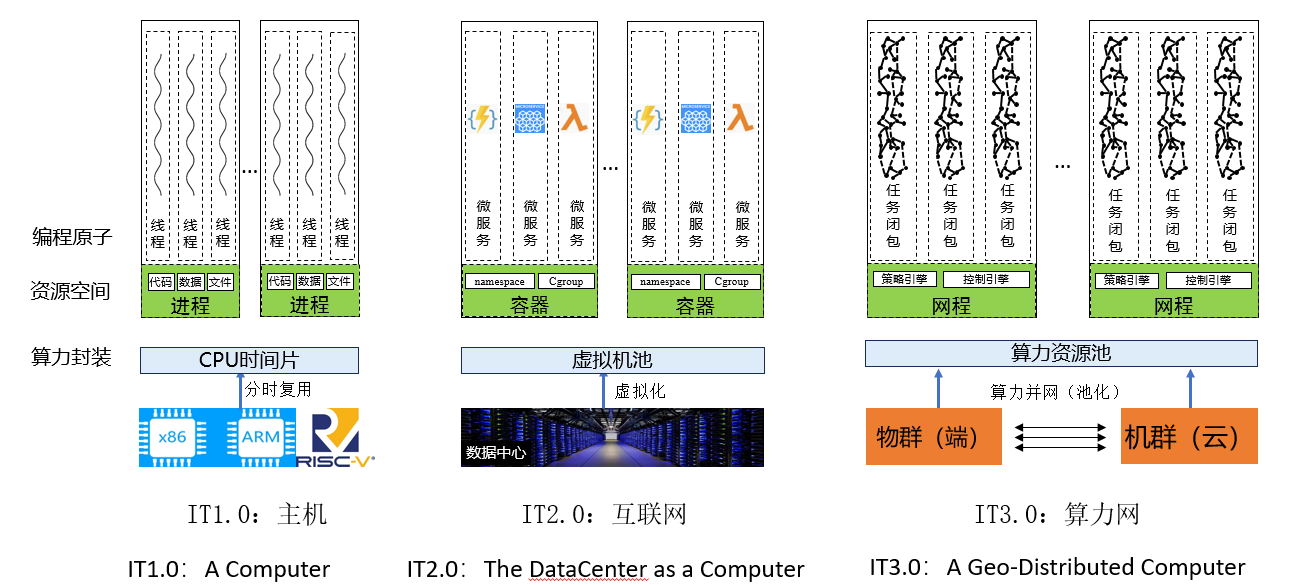
图13:任务闭包的本质
第二个巨大挑战是实现算力网的两个核心变化,即算力资源“全局统一”和供需各方“环节解耦”。“全局统一”是指在广域范围内分布的异地、异属、异构的算力资源,在逻辑上对上层应用抹平差异,从而实现资源的全域命名、算力资源统一的池化抽象、算力使用的单一实时计量、算力使用的“网页化”编程、算力任务的广域路由、算力负载的跨平台迁移等各个层次的“单一映像”(如图14)。“环节解耦”是指在算力网生态构成中,通过技术手段支持更多的细分角色,如算力提供商、算力运营商、算力增值服务商、算力消费商等,解除云计算生态中算力供应商对算力消费者的绑定,解除算力应用对特定算力芯片的依赖,构建一个真正开放、对创新者友好、更加安全的算力基础设施生态(如图15)。
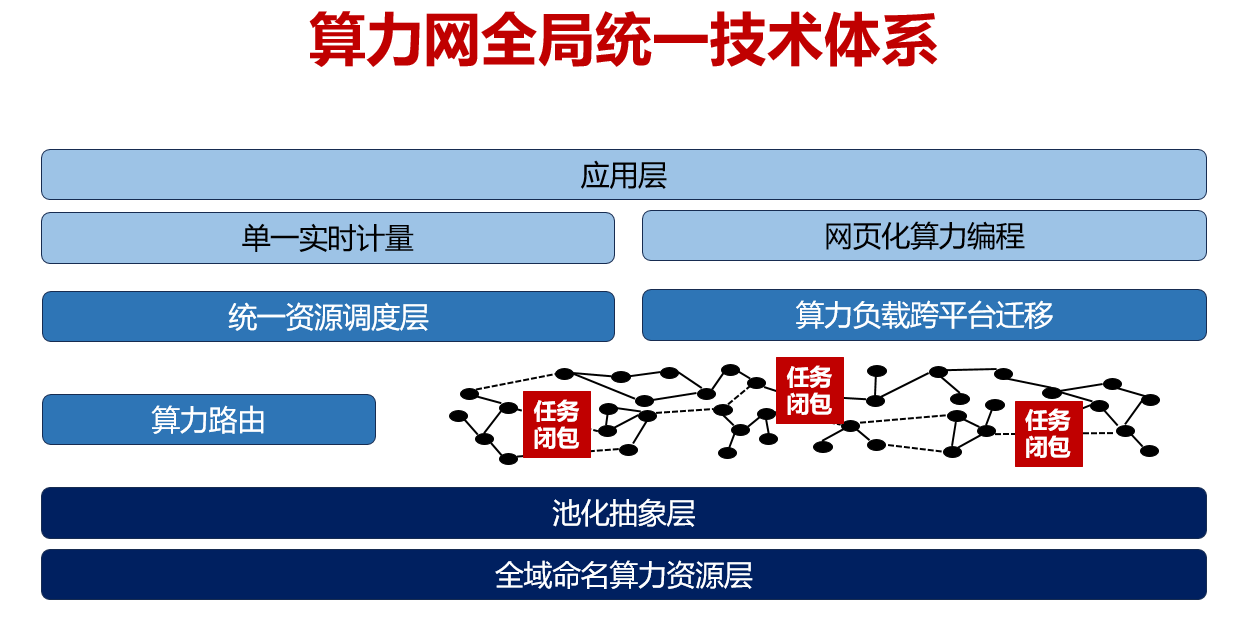
图14:算力网全局统一技术体系
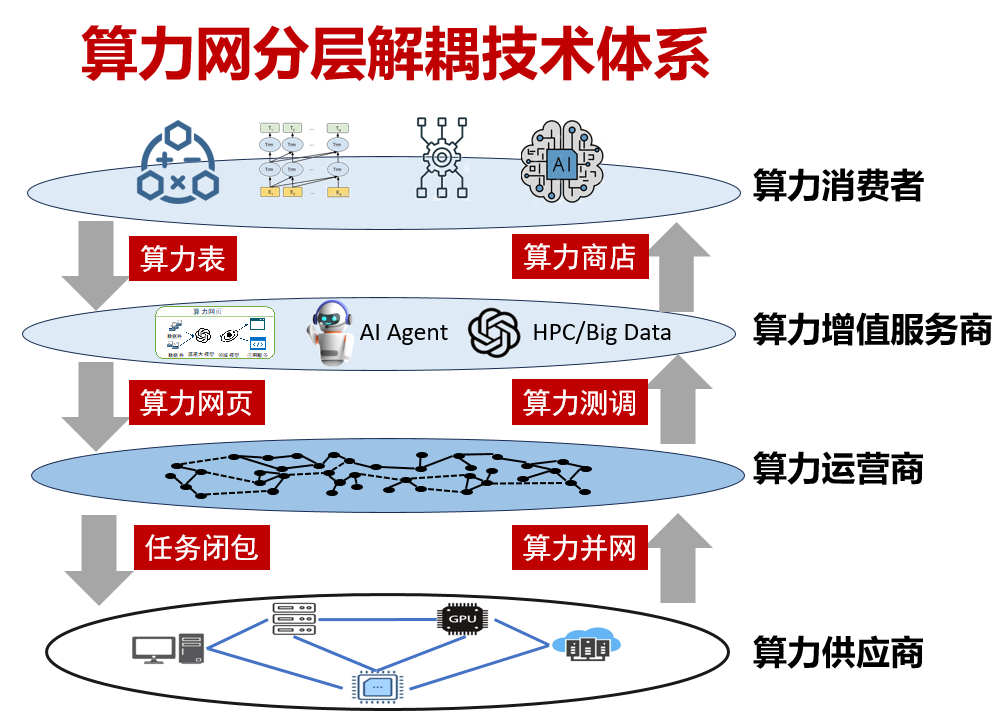
图15:算力网分层解耦技术体系
第三个巨大挑战是打造算力基础设施中国方案的全球比较优势。建设算力基础设施的目的是实现对信息化的广泛支撑。首先分析一下在不同时期我国信息化的全球比较优势(如图16),其中横坐标是问题的规模和场景,纵坐标是对开发者的要求,这两个维度是决定产业规模的核心要素。信息化的第一个阶段是位于左下角象限的信息管理系统(MIS)时期,信息化项目的特点是碎片化,而且无需深度领域知识支持,没有算法挑战,利润低,所以美国把这部分业务外包给中国和印度了。信息化的第二个阶段是位于右上角象限的互联网平台时期,美国依靠技术的领先优势引领全球,中国则依靠人口规模红利和互联网行业对全中国人才的虹吸效应,在全球竞争中处于优势地位。信息化的第三个阶段是位于左上角象限的大数据与机器学习时期,美国依靠技术的领先优势和高端人才数量优势,在全球处于绝对领先地位,中国则处于跟随与苦苦追赶的态势,工业等行业的智能化很难形成可广泛推广的范式。信息化的第四个阶段进入了右下角象限的大模型时期,AI+开始广泛渗透到各行各业,对它们进行智能化改造,对开发者要求低,场景规模大,而中国的特色正好是工程师总量大,场景多。以此为背景,我国可以在算力基础设施上形成具备全球比较优势的技术与建设方案,在大幅度降低算力使用成本、大幅度降低算力使用门槛的同时,为包括“一带一路”国家在内的最广范围覆盖的人群提供高通量、高品质的智能服务。

图16:信息化比较优势对比图
人工智能技术的规模化推广要解决应用长尾问题,为80%的中小微企业提供低价格的算力、低门槛的服务。算力网的中国方案需要具备 “两低一高”,即“低成本、低门槛、高通量”。“低成本”是指在供给侧,大幅度降低算力器件、算力设备、网络连接、数据获取、算法模型调用、电力消耗、运营维护、开发部署的总成本,让广大中小企业都消费得起高品质的算力服务,有积极性开发算力网应用。“低门槛”是指在消费侧,大幅度降低广大用户的算力使用门槛,面向大众的公共服务必须做到易获取、易使用,像水电一样即开即用,像编写网页一样轻松定制算力服务,开发算力网应用。“高通量”是指实现低熵、高通量的算力服务,其中高通量代表算力服务的数量,是指在提供高并发度服务的同时,保证端到端服务的响应时间可满足率,即通量=并发度*响应时间可满足率。低熵代表算力服务的质量,是指在高并发负载中出现对资源无序竞争的情况下,保障系统的通量不急剧下降。简而言之,算力1.0时期的目标是“算得快”,算力2.0时期的目标是“算得省”,算力3.0时期的目标是“算得多”,而“算得多”对中国尤其重要。
五、 算法基础设施
算法是计算机科学的核心,凝聚着计算机科学家的智慧,也是很多IT产品的关键模块,但是它既不能申请专利,自身也不能成为产品,以AI算法为核心的创业公司大多不太成功。AI大模型第一次实现了算法的基础设施化,提供“模型即服务”(MaaS)。传统的数值计算算法(Numerical Computation)是对数理知识建模,如BLAS库模型、有限元等,每个模型解决一小类问题,属于小模型,通过数学库和求解器的形式提供调用。计算机科学基础算法(Fundamental of Computer Science)如图、概率、搜索等方法,也属于小模型,通过算子库的形式提供调用。这些传统算法如何基础设施化是个困难的问题。一个复杂应用需要调用不同的模型,当前模型之间没有通用、标准的调用方式。解决了模型之间的互操作问题,才能突破复杂问题求解的边界。
最后,数据空间基础设施需要一个通用引擎,用来统一表达复杂智能任务。随着AI Agent的发展,它有可能成为新的算力网通用引擎。实现统一的复杂任务表达需要设计用户编程语言、程序和通用执行引擎,在计算空间上它们是C语言、并行程序和编译器,在信息空间它们是Java语言、信息网页和浏览器,在数据空间它们可能是python语言、算力网页和AI Agent。其中,编译器解决了计算应用的跨平台迁移,Java虚拟机解决了智能终端应用的跨平台迁移,那么什么技术能解决智能云端应用的跨算力平台迁移?
数据基础设施的目标是将互联网时代的“信息在线”升级到智能时代的“智能在线”。做到始终在线(on-line)是信息服务的终极目标。需要把数据场、算力网和“模型即服务”统一变成一个基础设施,通过算力网页表达复杂的智能应用需求,让智能始终在线。数据基础设施让智能应用以更简单的表达方式使用算力、数据与算法,智能应用程序员更专注于业务功能的低门槛实现(如图17)。
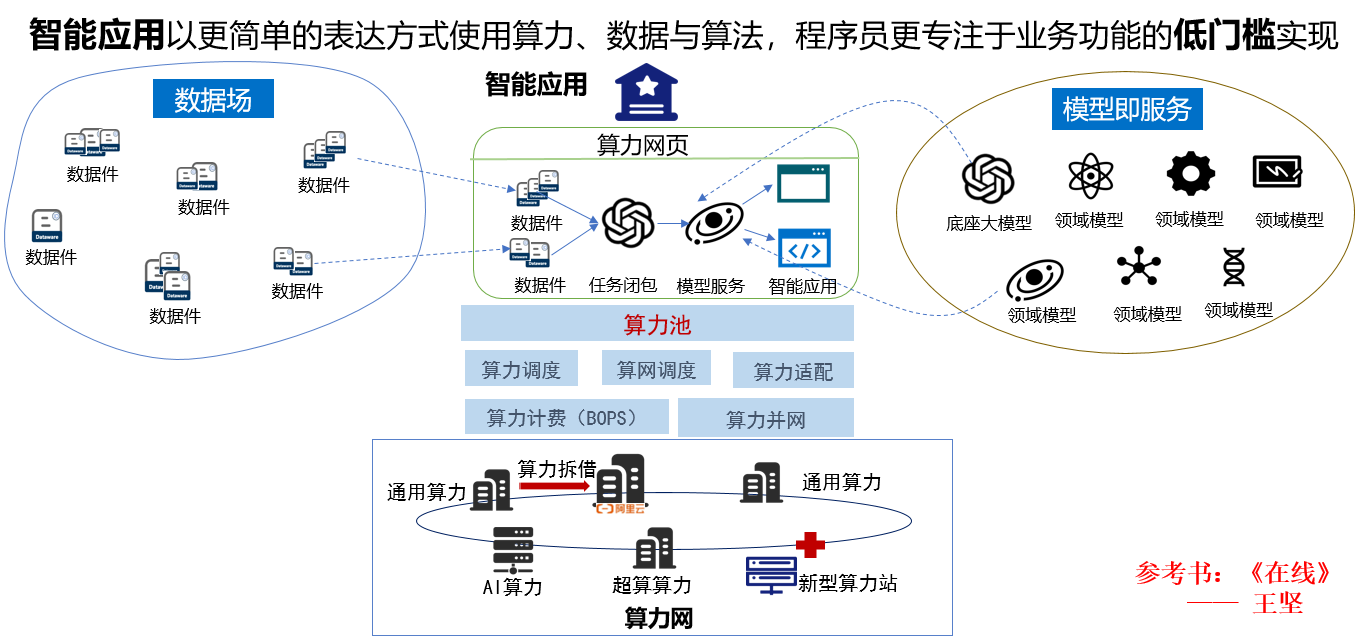
图17:基于数据基础设施实现智能在线
六、 未来
网络空间在2020年来到了新的历史关口,在过去40年围绕信息冲浪(surfing)创造了整个互联网技术体系和庞大的应用生态,未来30年围绕数据冲浪能否创造出算力网技术体系和新的应用生态?信息冲浪是人或者APP由通用浏览器引擎作为入口,通过网络七层协议,到Web Server,再操作全网共享的信息网页。数据冲浪是由人、APP或者物由AI Agent引擎作为入口,通过新协议(包括算力路由、数据件协议簇等),到模型Server,再操作全网共享的数据件(如图18)。
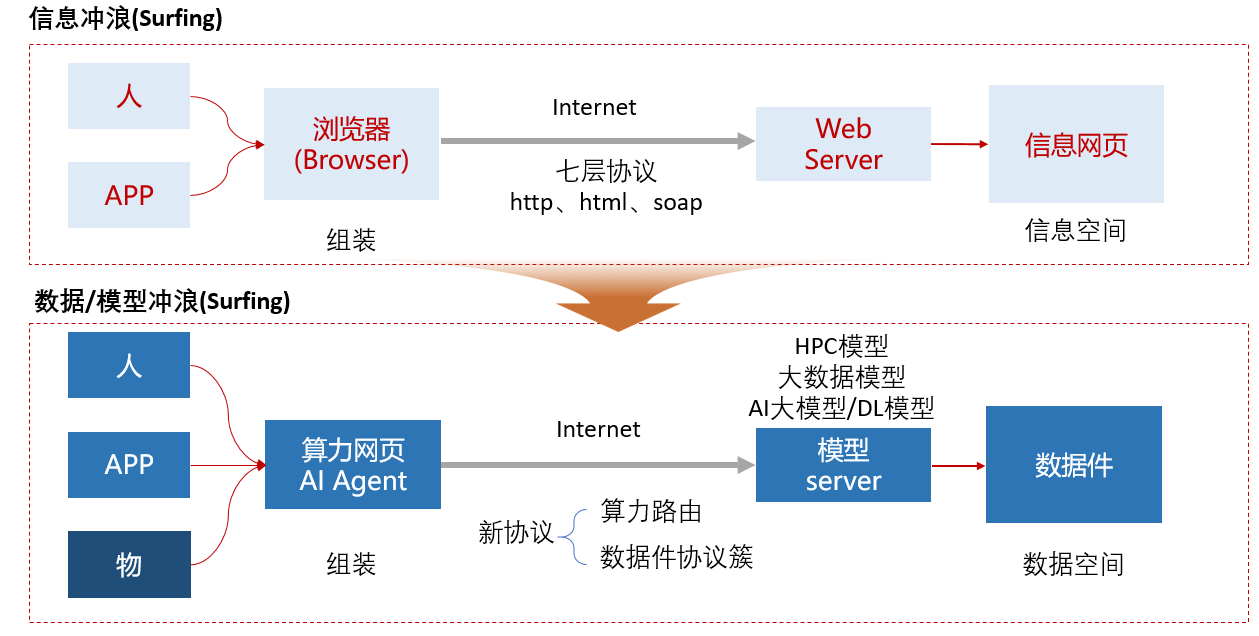
图18:数据空间技术体系图
网络空间已经形成了信息空间的四层架构(如图19),即第一层云主机,第二层通信基础设施,第三层互联网基础设施,第四层WEB基础应用。未来的数据空间也将形成四层架构,即第一层算力站(算力池化),第二层未来网络(包括6G和算力网络),第三层数据基础设施,包括模型即服务、算力网、数据场紧耦合在一起,第四层智能体。新架构的网络空间将支撑我们进入智能时代。
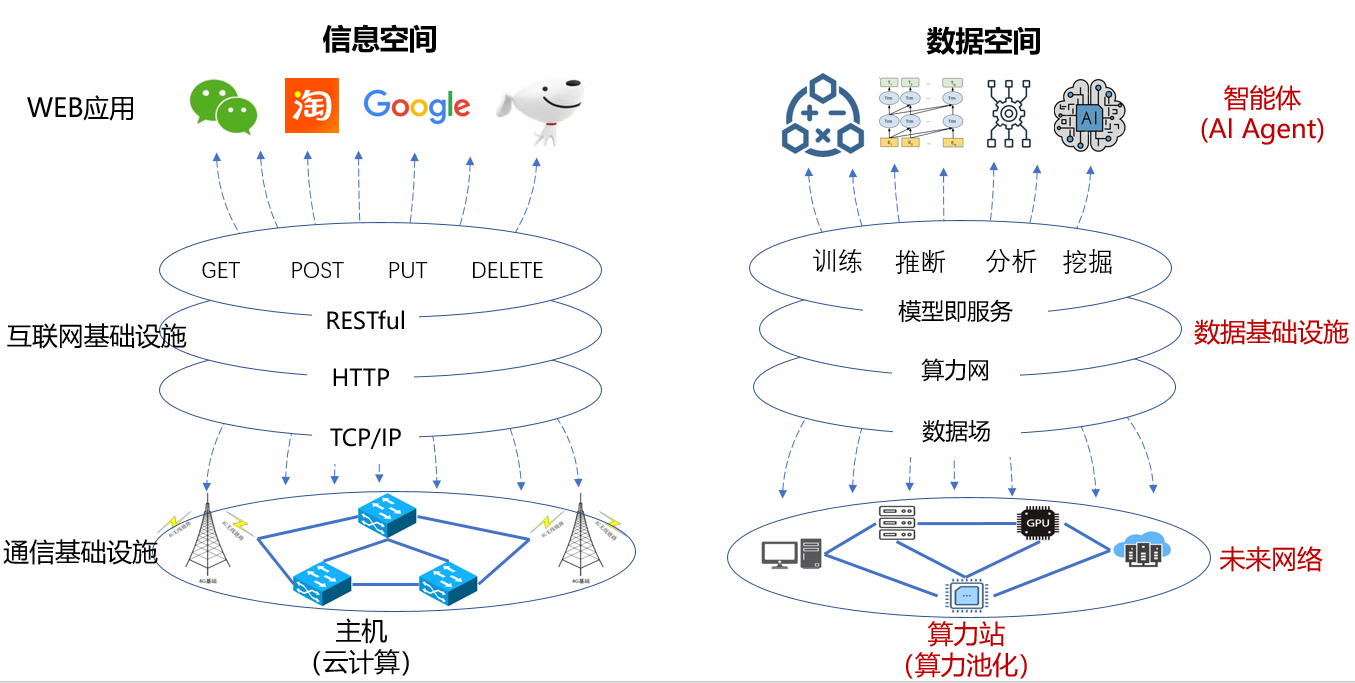
图19:网络空间架构图
我国在强起来的时代,科技必须自立自强,只有通过完整技术体系的创造,才能抢占科技制高点。
(根据孙凝晖院士在2024年计算所春季战略规划会上的报告整理)